SQL SERVER基本知识整理
Contents
- 1.数据库—DDL
- 2.数据表-DML
- 3. 数据表-修改约束
- 4. 数据查询-SELECT
- 5. 嵌套查询
- 6. 多表连接查询
- 7. 权限操作
- 8. 数据输出-PRINT
- 9. 流程控制
- 10.定义一个数据类型
- 11.使用聚合函数统计汇总
- 12.使用排序函数
- 13. 其他各类函数(1)
- 13.1. ASCII()函数
- 13.2. CHAR()函数
- 13.3. LEFT()函数,RIGHT()函数
- 13.4. LTRIM()和RTRIM()函数
- 13.5. STR()函数-保留某数值的长度
- 13.6. REVERSE(s)-逆序输出
- 13.7. LEN(STR)-计算字符串的长度
- 13.8. CHARINDEX(x)-计算字符的所在位置
- 13.9. SUBSTRING(x)-保留字符串中的某一段
- 13.10. UPPER(x)函数-字母小写变大写
- 13.11. REPLACE(x)-替换
- 11.12. ABS(X)-返回X的绝对值
- 13.13. pi()函数-圆周率
- 13.14.FLOOR(X)-数据舍入
- 13.15. RAND(x)-随机函数
- 13.16. ROUND(x,y)-返回接近于参数x的数
- 13.17. SIGN(x)-返回参数的符号
- 13.18. CEILING(x)-向上取整
- 13.19. power(x,y)-计算数值表达式的指定幂次
- 13.20.SQUARE(x)-开平方
- 13.21.EXP(x)-冥运算函数
- 13.22. SQRT(x)-返回非负数x的二次方根
- 13.23. LOG(x)和LOG10(x)-对数运算函数
- 13.24. RADIANS(x)、DEGREES(x)-角度与弧度相互转换的函数
- 13.25. SIN(x)和ASIN(x)
- 13.26. COS(x)和 ACOS(x)
- 13.27. TAN(x)、ATAN(x)、COT(x) – 正切余切
- 14.其他各类函数(2)
- 14.1. CAST() 和 CONVERT()-转换函数
- 14.2. TEXTPTR()-文本指针
- 14.3. TEXTVALID()-检查特定文本指针是否有效
- 14.4. GETDATE()-返回数据库系统的日期和时间
- 14.5. UTCDATE()-返回当前的UTC日期值
- 14.6. DAY(d)-返回月内指定日期的天数
- 14.7. MONTH(d)-返回指定日期d中月份的整数值
- 14.8. YEAR(d)-返回指定日期d中年份的整数值
- 14.9. DATENAME(dp,d)-返回日期中定制部分的整数值
- 14.10. DATEADD(dp,num,d)-返回指定日期加上一个时间段的新日期
- 14.11. COL_LENGTH(table,column-返回表中指定字段的长度值
- 14.12. COL_NAME(table_id,column_id)-返回表中指定字段的名称
- 14.13. DATALENGTH(expression)-返回数据表达式得数据得实际长度
- 14.14. DB_ID(database_name)-返回数据库得编号
- 14.15. DB_NAME(database_id)- 函数返回数据库得名称
- 14.16. GETANSINULL(database_name) – 返回当前数据库默认得NULL值
- 14.17. HOST_ID() – 返回计算机得标识号
- 14.18. HOST_NAME – 返回服务端计算机名称
- 14.19. OBJECT_ID() – 返回数据库对象编号
- 14.20. SUSER_ID – 返回用户的SID
- 14.21. SUSER_SNAME – 返回用户的登录名
- 14.22. OBJECT_NAME – 返回数据库对象名称
- 14.23. USER_ID – 返回数据用户ID
- 14.24. USER_NAME(1) – 返回数据库用户名
- 15.动态查询
- 16.经典习题
- 17.其他
- 18.疑难解惑
1.数据库—DDL
1.1.创建数据库-CREATE
CREATE DATABASE test_db
ON
(
NAME = test_db,
FILENAME = 'D:\SQL server 2019\test\test_db.mdf',
SIZE = 6,
MAXSIZE = 10,
FILEGROWTH = 1
)
LOG ON
(
NAME = test_log,
FILENAME = 'D:\SQL server 2019\test\test_db_log',
SIZE = 1MB,
MAXSIZE = 2MB,
FILEGROWTH = 1
)
GO
CREATE DATABASE [sample_db] ON PRIMARY
(
NAME = 'sample_db',
FILENAME = 'D:\SQL server 2019\sample\sample.mdf',
SIZE = 512KB,
MAXSIZE = 30MB,
FILEGROWTH = 5%
)
LOG ON
(
NAME = 'sample_log',
FILENAME = 'D:\SQL server 2019\sample\sample_log.ldf',
SIZE = 1024KB,
MAXSIZE = 8192KB,
FILEGROWTH = 10%
)
GO
CREATE DATABASE newDBdata on PRIMARY
(
NAME = 'newDBdata',
FILENAME = 'D:\SQL server 2019\newDBdata\newDBdata.mdf',
SIZE = 2MB,
MAXSIZE = 20MB,
FILEGROWTH = 10%
)
LOG ON
(
NAME = 'newDBlog',
FILENAME = 'D:\SQL server 2019\newDBdata\newDBlog.ldf',
SIZE = 1MB,
FILEGROWTH = 5%
)
#关于ON PRIMARY
SQL Server中的ON PRIMARY表示将表或数据库对象存储在主文件组中。在创建表或数据库对象时,可以通过ON PRIMARY指定该对象存储在主文件组中。如果未指定文件组,则默认存储在主文件组中,因此ON PRIMARY可以省略。
1.2.创建数据表-CREATE
CREATE TABLE authors
(
auth_id int PRIMARY KEY, #整型,数据库主键
auth_name VARCHAR(20) NOT NULL unique, #可变长字符串;不能为空;不能重复
auth_gender tinyint NOT NULL DEFAULT(1) #性别
)
USE test_db
GO
CREATE TABLE teacher
(
id INT NOT NULL PRIMARY KEY,
name VARCHAR(20) NOT NULL,
birthday DATE,
sex VARCHAR(4),
cellphone VARCHAR(18)
)
1.3.修改数据库参数-MODIFY FILE
ALTER DATABASE sample_db
MODIFY FILE
(
NAME=sample_db,
SIZE=15MB #修改初始大小
)
GO
ALTER DATABASE sample_db
MODIFY FILE
(
NAME=sample_db,
MAXSIZE=50MB #修改最大容量
)
GO
1.4.删除数据库-DROP
DROP DATABASE sample_db; #删除数据库
1.5.重命名数据-MODIFY NAME
ALTER DATABASE sample_db
MODIFY NAME = sample_db2; #修改数据库名
1.6.重命名数据库-EXEC sp_renamedb
exec sp_renamedb 'test_db','test_db1';
1.8.重命名列名-EXEC sp_rename
EXEC sp_rename 'authors.auth_name1','auth_name2','COLUMN';
2.数据表-DML
2.1.增加字段-ALTER ADD
方法一:点击表,右键设计
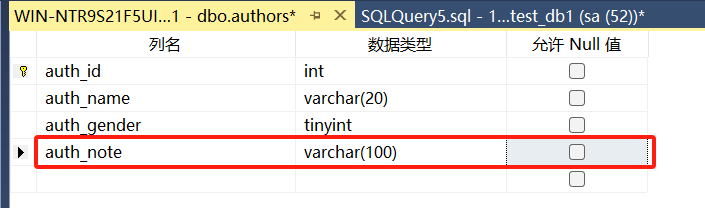
方法二:存储过程增加字段
ALTER TABLE authors
ADD auth_note VARCHAR(100) NULL
ALTER TABLE AUTHORS
ADD birth DATE NOT NULL
2.2.修改字段类型-ALTER ALTER
ALTER TABLE authors
ALTER COLUMN auth_phone VARCHAR(15)
2.3.删除字段-ALTER DROP
ALTER TABLE authors DROP COLUMN birthdate
2.4.整个表删除-DROP
DROP TABLE authors
2.5.问题1:修改表后不能保存
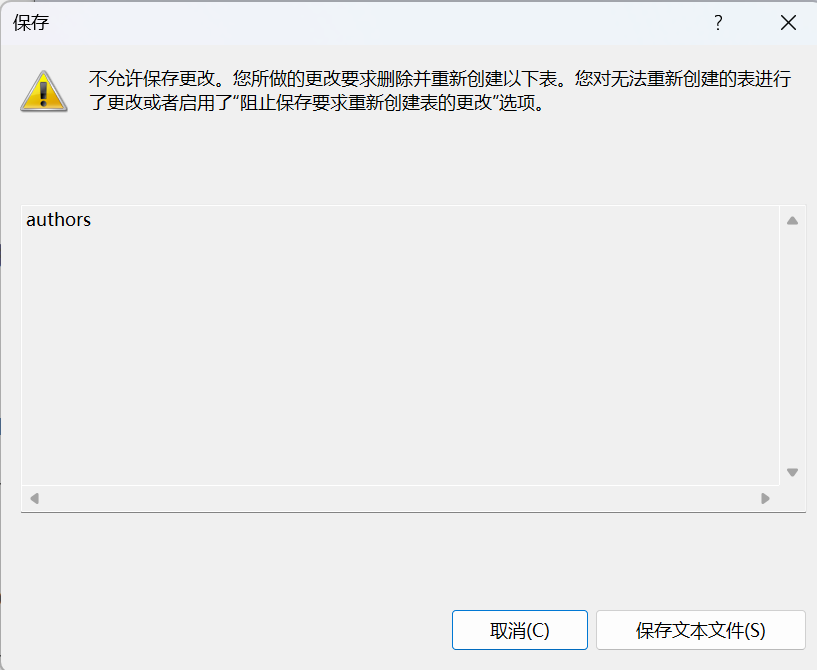
工具-》选项-》设计器-》取消勾选“阻止保存要求重新创建表的更改”
2.6.数据的插入-INSERT
insert into teacher VALUES (1,'张三','1978-02-14','男','0018611')
SELECT * FROM teacher
SELECT * FROM teacher
INSERT INTO teacher VALUES (2,'李四','1978-11-21','女','0018624'),(3,'王五','1976-12-05','男','0018678'),(4,'赵纤','1980-6-5','女','0018699');
SELECT * FROM teacher
2.7.数据的更改-UPDATE
SELECT * FROM teacher WHERE id = 1;
UPDATE teacher
SET birthday = '1980-8-8',cellphone='0018600' WHERE id = 1;
SELECT * FROM teacher WHERE id = 1;
SELECT * FROM teacher;
UPDATE teacher SET cellphone = '01008611';
SELECT * FROM teacher;
2.8.数据删除-DELETE
delete from teacher where id = 1;
select * from teacher where id = 1;
select * from teacher;
delete from teacher; #删除所有记录
select * from teacher;
3. 数据表-修改约束
3.1. 添加主键约束和唯一性约束
CREATE TABLE table_emp
(
e_id CHAR(18) PRIMARY KEY, #主键
e_name VARCHAR(25) NOT NULL,
e_deptID INT,
e_phone VARCHAR(15) CONSTRAINT uq_phone UNIQUE #唯一性约束
)
3.2. 增加约束
use test_db1
alter table teacher add constraint uq_id unique(id);
3.3. 删除约束
alter table teacher drop constraint uq_id;
4. 数据查询-SELECT
4.1.查看数据库状态
select DATABASEPROPERTYEX('database_name','status') #显示“当前”数据库状态
sp_spaceused #显示“当前”数据库使用和保留空间
sp_helpdb #查看“所有”数据库的基本信息
use test_db1
select DATABASEPROPERTYEX('test_db1','status') AS '数据库状态'
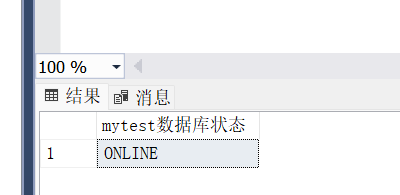
sp_spaceused #显示数据库使用和保留空间
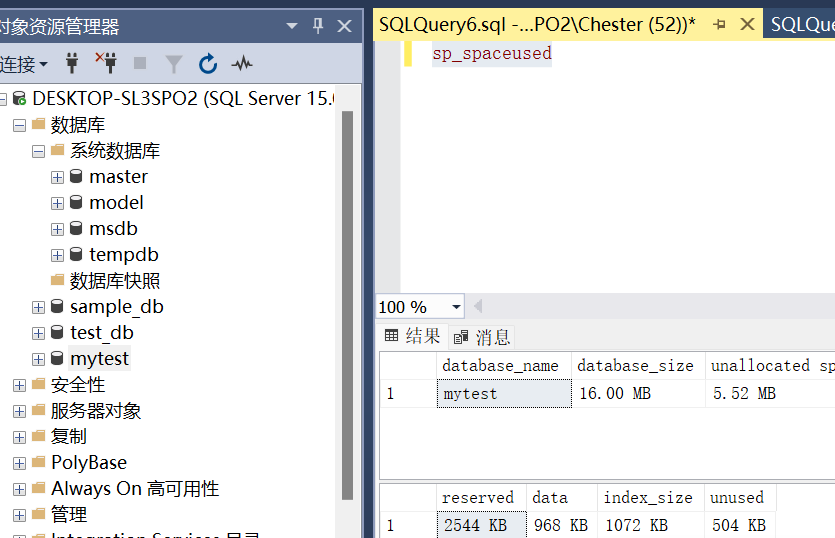
sp_helpdb #查看所有数据库的基本信息
4.2.查看某个数据库里面的所有表
SELECT TABLE_NAME
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_TYPE = 'BASE TABLE'
AND TABLE_CATALOG = '你的数据库名';
4.3.常用查找方法
#先生成数据表
USE test_db1
GO
CREATE TABLE stu_info
(
s_id INT PRIMARY KEY,
s_name VARCHAR(40),
s_score INT,
s_sex CHAR(2),
s_age VARCHAR(90)
);
INSERT INTO stu_info
VALUES (1,'许三',98,'男',18),
(2,'张靓',70,'女',19),
(3,'王宝',25,'男',18),
(4,'马华',10,'男',20),
(5,'李岩',65,'女',18),
(6,'刘杰',88,'男',19);
USE test_db
GO
SELECT * FROM stu_info;
SELECT s_name,s_score FROM stu_info;
SELECT s_name,s_score,s_score-5 AS new_score FROM stu_info;
SELECT * FROM stu_info WHERE s_sex='男';
SELECT * FROM stu_info WHERE s_sex='男' AND s_score > 80;
SELECT * FROM stu_info WHERE s_score > 80 OR s_age > 18;
USE test_db
GO
SELECT * FROM stu_info WHERE s_name NOT LIKE '%刘%'
4.4. 消除重复-DISTINCT
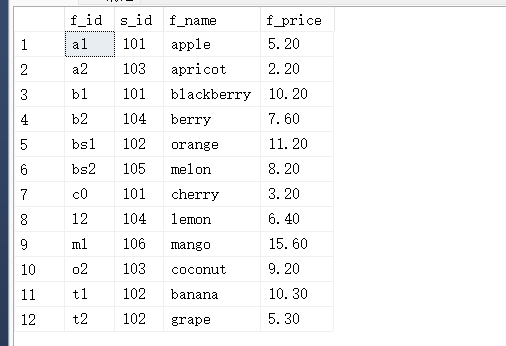
USE test_db
CREATE TABLE fruits
(
f_id char(10) PRIMARY KEY, --水果ID
s_id INT NOT NULL, --供应商ID
f_name VARCHAR(255) NOT NULL, --水果名称
f_price decimal(8,2) NOT NULL, --水果价格
);
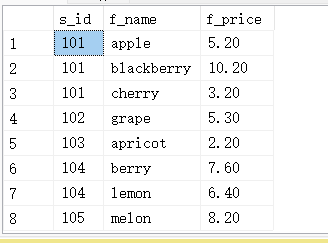
INSERT INTO fruits (f_id,s_id,f_name,f_price) VALUES ('a1',101,'apple',5.2),('b1',101,'blackberry',10.2),('bs1',102,'orange',11.2),('bs2',105,'melon',8.2),('t1',102,'banana',10.3),('t2',102,'grape',5.3),('o2',103,'coconut',9.2),('c0',101,'cherry',3.2),('a2',103,'apricot',2.2),('l2',104,'lemon',6.4),('b2',104,'berry',7.6),('m1',106,'mango',15.6);
SELECT f_id,s_id,f_name,f_price FROM fruits;
使用DISTINCT消除重复
SELECT DISTINCT s_id FROM fruits;
4.4.返回前n行-TOP
SELECT TOP 3 * FROM stu_info;
SELECT TOP(3) * FROM fruits;
SELECT TOP 30 PERCENT * FROM fruits;
4.5.查询别名-AS
SELECT f_name AS '名称',f_price AS '价格' from fruits;
SELECT '名称'=f_name,'价格'=f_price FROM fruits;
SELECT '供应商编号:',s_id,'水果编号:',f_id FROM fruits;
SELECT f_name,f_price 原价,f_price * 0.8 折扣价 FROM fruits;
4.6. 条件查询查询-WHERE
SELECT f_name,f_price From fruits WHERE f_price = 10.2;
SELECT f_name,f_price From fruits WHERE f_name='apple';
SELECT f_name,f_price From fruits WHERE f_price<10;
4.7. 两个数值之间-BETWEEN AND
SELECT f_name,f_price FROM fruits WHERE f_price BETWEEN 2.00 and 10.20;
4.8.匹配列出选项-IN,NOT IN
SELECT s_id,f_name,f_price FROM fruits WHERE s_id IN (101,102);
SELECT s_id,f_name,f_price FROM fruits WHERE s_id NOT IN (101,102);
4.9 模糊查询-LIKE + 通配符
SELECT f_id,f_name FROM fruits WHERE f_name LIKE 'b%'; #b字母开头的
SELECT f_id,f_name FROM fruits WHERE f_name LIKE '%g%'; #包含字母'g'的记录
SELECT f_id,f_name FROM fruits WHERE f_name LIKE 'b%y'; #b开头y结尾
SELECT f_id,f_name FROM fruits WHERE f_name LIKE '____y'; #一个_代表一个字符
SELECT f_id,f_name FROM fruits WHERE f_name LIKE '[abc]%'; #[]指定一个字符集合,只要匹配其中任何一个字符,即为所查找的文本。
SELECT f_id,f_name FROM fruits WHERE f_name LIKE '[^abc]%'; #^匹配不以指定集合中的任何字符开头
SELECT * FROM stu_info WHERE s_name like '马%';
SELECT * FROM stu_info WHERE s_name like '[张王李]%';
创建一个新的表
USE test_db
GO
CREATE TABLE customers
(
c_id char(10) PRIMARY KEY,
c_name varchar(255) NOT NULL,
c_email varchar(50) NULL,
);
INSERT INTO customers (c_id,c_name,c_email)
VALUES('10001','RedHook','LMing@163.com'),
('10002','Stars','jerry@hotmail.com'),
('10003','RedHook',NULL),
('10004','JOTO','sam@hotmail.com');
SELECT c_id,c_name,c_email FROM customers WHERE c_email IS NULL; #查找空值
SELECT c_id,c_name,c_email FROM customers WHERE c_email IS NOT NULL; #非空值
4.10. 布尔子句-EXISTS
在 SQL Server 中,EXISTS 是一个布尔子句,用于检查子查询是否返回任何行。如果子查询返回至少一行数据,EXISTS 将返回 TRUE;如果子查询没有返回任何行,EXISTS 将返回 FALSE。EXISTS 通常用于 WHERE 或 HAVING 子句中,以基于另一个查询的结果来过滤数据。
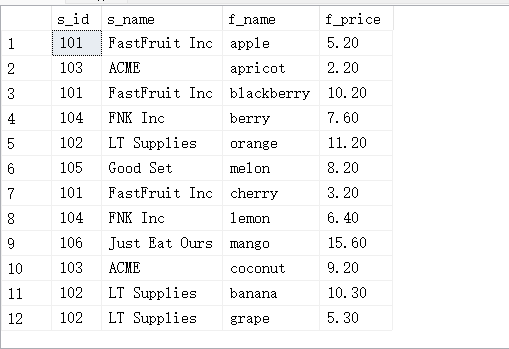
USE test_db
GO
CREATE TABLE suppliers
(
s_id char(10) PRIMARY KEY,
s_name varchar(50) NOT NULL,
s_city varchar(50) NOT NULL
);
INSERT INTO suppliers(s_id,s_name,s_city) VALUES('101','FastFruit Inc','Tianjin'),('102','LT Supplies','shanghai'),('103','ACME','beijing'),('104','FNK Inc','zhengzhou'),('105','Good Set','xinjiang'),('106','Just Eat Ours','yunnan'),('107','JOTO meoukou','guangdong');
#“EXISTS”利用子查询来判断TURE和FALSE,TURE继续外层查询,FLASE则停止。
SELECT * FROM fruits
WHERE EXISTS
(SELECT s_name FROM suppliers WHERE s_id = 107);
#子查询能进行,才能进行外层查询
SELECT * FROM fruits
WHERE f_price >10.20 AND EXISTS
(SELECT s_name FROM suppliers WHERE s_id = 107);
4.11. 升降排序-ORDER BY
SELECT f_name FROM fruits ORDER BY f_name;
#顺序排列
SELECT f_name,f_price FROM fruits ORDER BY f_name,f_price;
#多列排序
SELECT f_name,f_price FROM fruits ORDER BY f_price DESC;
#降序排列
SELECT * FROM stu_info ORDER BY s_score DESC;
#降序排列
4.12. 分组排序-GROUP BY
SELECT s_id,COUNT(*) AS Total FROM fruits GROUP BY s_id;
#COUNT()函数,把数据分为多个逻辑组,并对每个组进行集合计算。

SELECT s_id,f_name FROM fruits group by s_id,f_name;
#先按第一个字段来分组,再按第二个字段

SELECT s_id,count(*) AS Total FROM fruits GROUP BY s_id HAVING count(*) >1;
#使用HAVING对分组结果再过滤

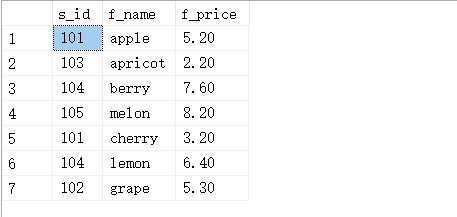
4.13. 合并结果排序-UNION
#不使用union all
SELECT s_id,f_name,f_price FROM fruits WHERE f_price < 9.0;
#使用union all
SELECT s_id,f_name,f_price FROM fruits WHERE f_price < 9.0 UNION ALL SELECT s_id,f_name,f_price FROM fruits WHERE s_id = 101;
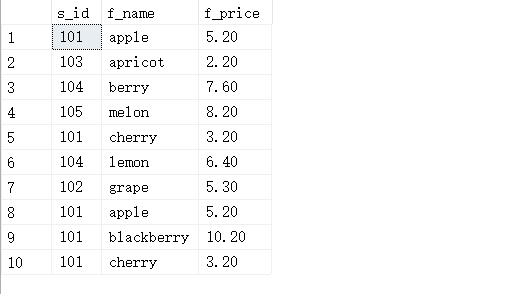
#使用union
#UNION不使用关键字ALL,执行的时候会删除重复的记录,所有返回的行都是唯一的;使用关键字ALL的作用是不删除重复行也不对结果进行自动排序
SELECT s_id,f_name,f_price FROM fruits WHERE f_price < 9.0 UNION SELECT s_id,f_name,f_price FROM fruits WHERE s_id = 101;
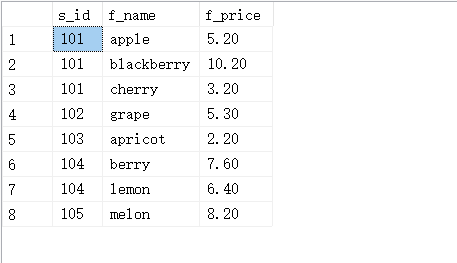
4.14.查找表里的所有约束
方法一:
SELECT
CONSTRAINT_NAME,
CONSTRAINT_TYPE
FROM
INFORMATION_SCHEMA.TABLE_CONSTRAINTS
WHERE
TABLE_NAME='ORDERS'
ORDER BY
CONSTRAINT_TYPE;
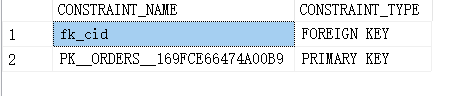
方法二:
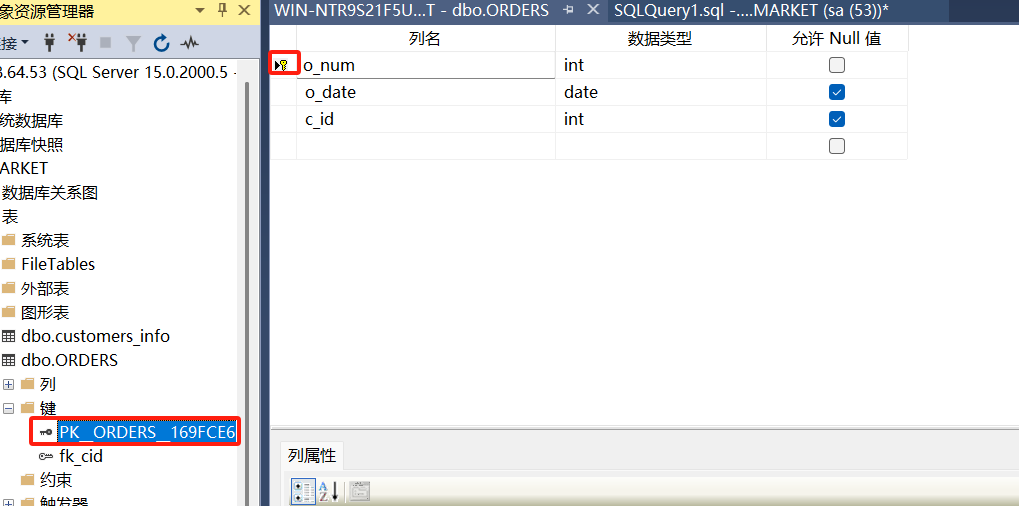
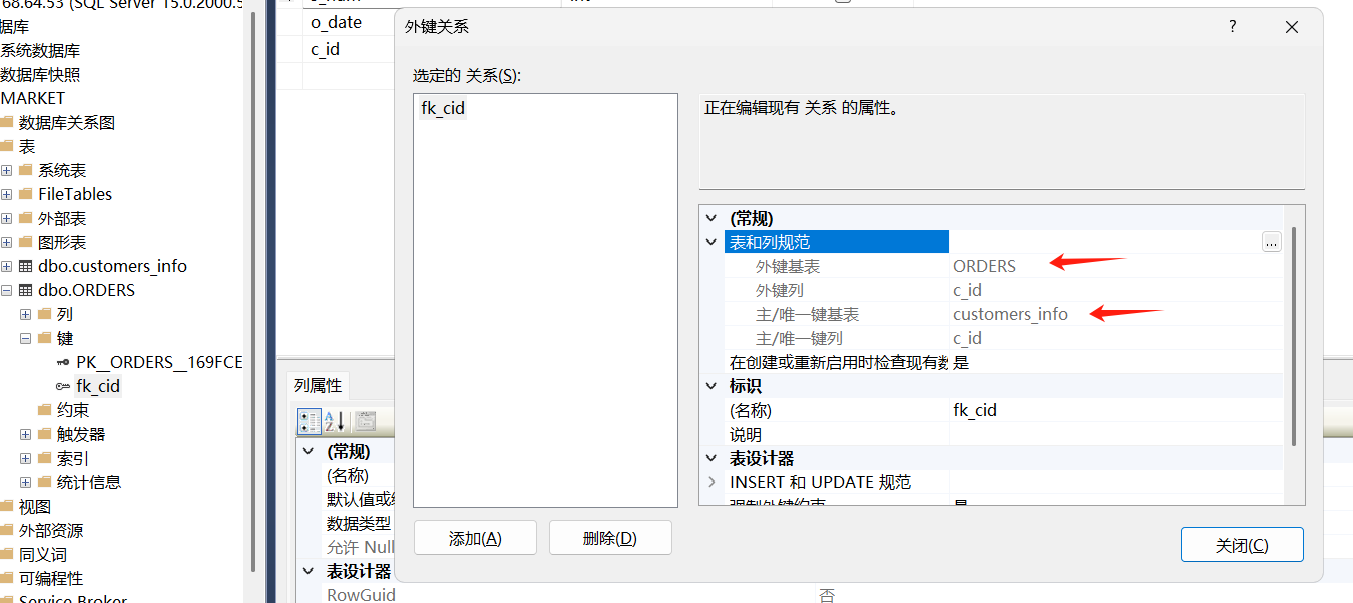
5. 嵌套查询
5.1. 使用比较运算符
#查找出产地为tianjin的水果
#查找出产地为tianjin的水果
use test_db1
select * from fruits;
select * from suppliers;
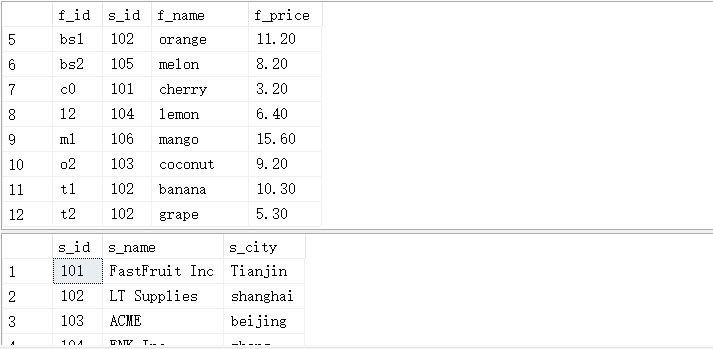
SELECT s_id,f_name FROM fruits
WHERE s_id =
(SELECT s1.s_id FROM suppliers AS s1 WHERE s1.s_city = 'Tianjin');
#查找出产地不是Tianjin的水果
SELECT s_id,f_name FROM fruits
WHERE s_id <>
(SELECT s1.s_id FROM suppliers AS s1 WHERE s1.s_city = 'Tianjin');
5.2 使用IN关键字
#IN相当于“=”
#找出水果表f_id='c0'相对应供应商
USE test_db
GO
SELECT s_name FROM suppliers WHERE s_id IN
(SELECT s_id FROM fruits WHERE f_id = 'c0');
#找出水果表f_id='c0'不相对应供应商
SELECT s_name FROM suppliers WHERE s_id NOT IN
(SELECT s_id FROM fruits WHERE f_id = 'c0');
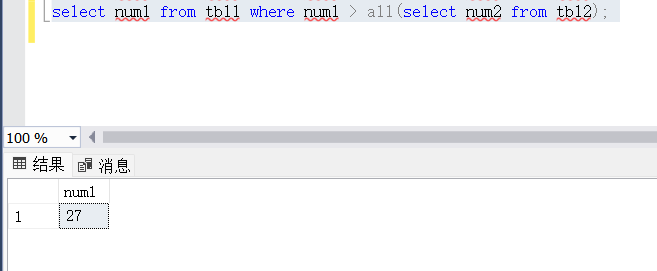
5.3. 使用ANY、SOME、ALL关键字
创建表
USE test_db
GO
CREATE table tbl1 (num1 INT NOT NULL);
CREATE table tbl2 (num2 INT NOT NULL);
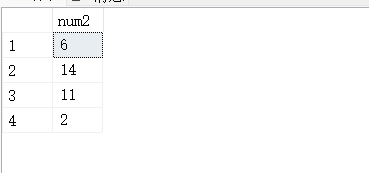
INSERT INTO tbl1 values(1),(5),(13),(27);
INSERT INTO tbl2 values(6),(14),(11),(20);
#tbl1表里面的其中一个值比tbl2里面任何一个值大,都会返回数值。
SELECT num1 FROM tbl1 WHERE num1 > ANY(SELECT num2 FROM tbl2);
#“ANY”如果与子查询返回的任何值比较结果为TRUE,则返回TRUE。

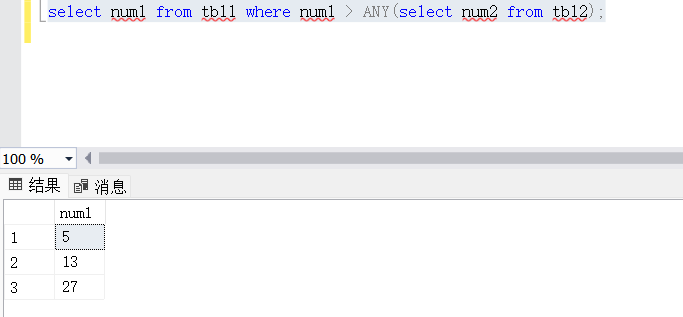
ANY和SOME在功能上是相同的,它们都可以用来与子查询返回的任何一个值进行比较。例如,SELECT column FROM table WHERE column > ANY (SELECT column FROM subquery) 表示如果主查询的列值大于子查询返回的任何一个值,则返回该行。
SOME是ANY的别名,主要用于区分关键字ANY和英文中的any。在实际使用中,两者可以互换使用,功能完全相桐
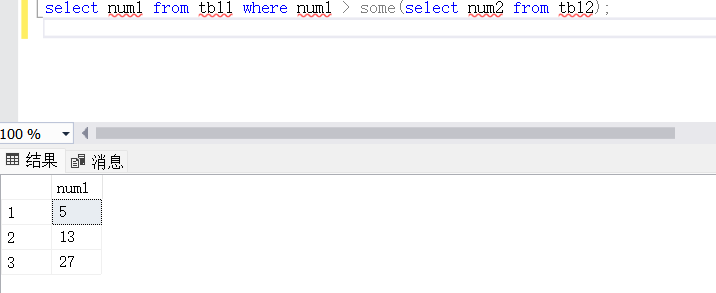
#必须要满足num1的里面其中一数值必须要比tbl2的所有数值都大,才会返回结果
SELECT num1 FROM tbl1 WHERE num1 > ALL(SELECT num2 FROM tbl2);
#"ALL"使用ALL时需要同时满足所有内层查询的条件。
6. 多表连接查询
6.1. 相等连接
#内连接
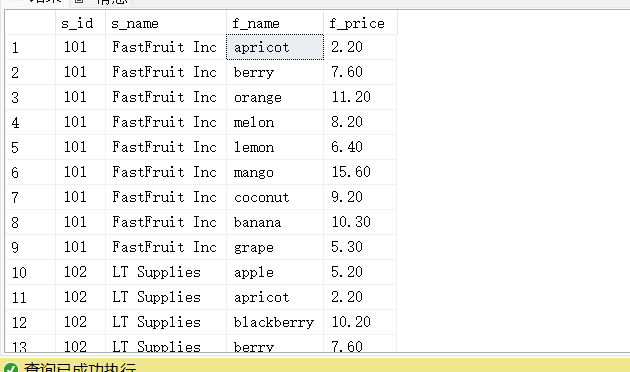
#fruits和suppliers表总都有相同含义的字段s_id,这两个数据表通过s_id字段建立联系。从fruits表中查询f_name和f_price字段,从suppliers表中查询s_id和s_name字段。
SELECT suppliers.s_id,s_name,f_name,f_price FROM fruits INNER JOIN suppliers
ON fruits.s_id = suppliers.s_id;
#依次按顺序来匹配需要的查询

6.2. 不等连接
#与不是对应s_id的供应商进行连接
SELECT suppliers.s_id,s_name,f_name,f_price FROM fruits INNER JOIN suppliers ON fruits.s_id <> suppliers.s_id;
6.3. 带选择条件的连接
SELECT fruits.s_id,suppliers.s_city FROM fruits INNER JOIN suppliers ON fruits.s_id = suppliers.s_id AND fruits.s_id = 101;
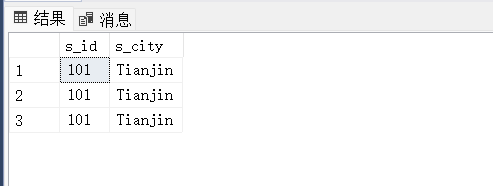
6.4. 自连接
SELECT f1.f_id,f1.f_name FROM fruits AS f1,fruits AS f2 WHERE f1.s_id = f2.s_id AND f2.f_id = 'a1';

6.5. 外连接
实验1
USE test_db
GO
CREATE TABLE student
(
s_id INT,
name VARCHAR(40)
);
CREATE TABLE stu_detail
(
s_id INT,
class VARCHAR(40),
addr VARCHAR(90)
);
INSERT INTO student VALUES(1,'wanglin1'),(2,''),(3,'zhanghai');
INSERT INTO stu_detail VALUES(1,'wuban','henan'),(2,'liuban','hebei'),(3,'qiban','');


6.5,1.左外连接
#返回包括左表中的所有记录和右表中连接字段相等记录
SELECT student.s_id,stu_detail.addr FROM student LEFT OUTER JOIN stu_detail ON student.s_id = stu_detail.s_id;

6.5.2.右外连接
#返回包括右表中的所有记录和右表中连接字段相等记录
SELECT student.name,stu_detail.s_id FROM student RIGHT OUTER JOIN stu_detail ON student.s_id = stu_detail.s_id;
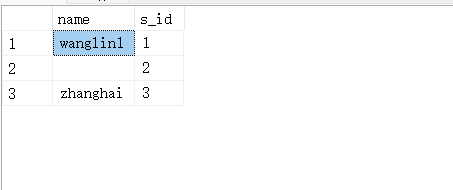
6.5.3.全外连接
#返回两个连接中所有的记录数据
SELECT student.name,stu_detail.addr FROM student FULL OUTER JOIN stu_detail ON student.s_id = stu_detail.s_id;

6.6.内连接,左外连接,右外连接,全外连接的区别
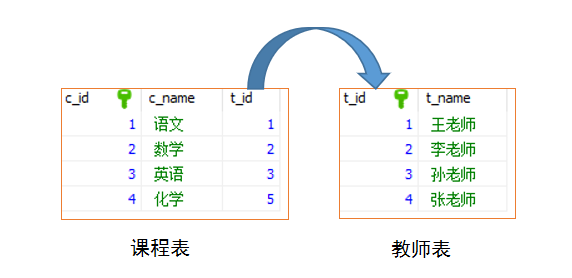
内连接,也叫等值连接, inner join得出同时存在t1表和t2表的数据集,通俗一点说就是求两个表的交集。
“inner join”两边的表的位置可以互换,结果都一样
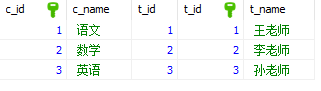
左连接:left [outer] join,左连接从左表取出所有记录,与右表匹配。如果没有匹配,以null值代表右边表的列。outer 可以不写,默认情况下不写outer关键字。
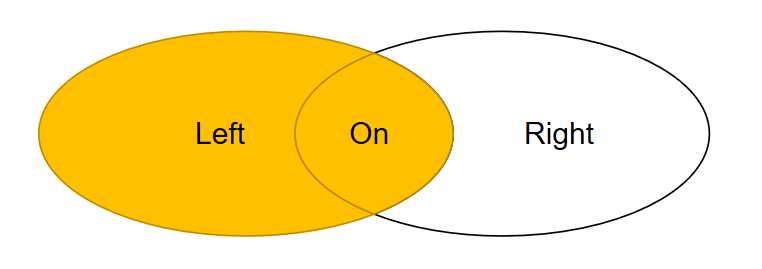
“left join”两边的表的位置不可以互换,交换后结果可能不一样。需要考虑好哪个是主表,哪个是从表。写在前面的是主表
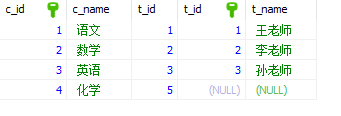
右连接:right [outer] join,右连接从右表取出所有记录,与左表匹配。如果没有匹配,以null值代表左边表的列。outer 可以不写,默认情况下不写outer关键字。
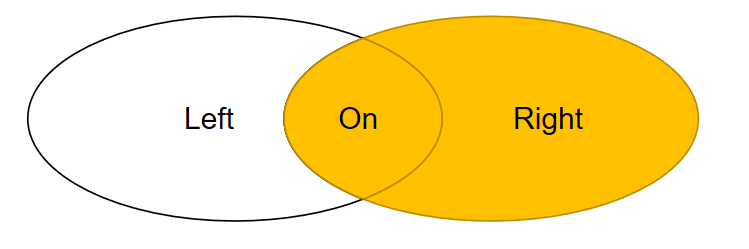
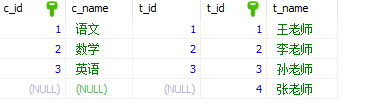
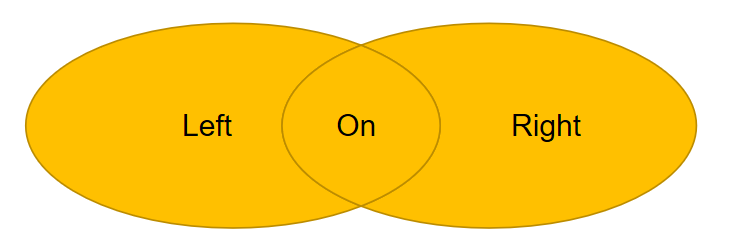
全连接:两个表的并集,MySQL暂不支持这种语句,不过可以使用union将两个结果集“堆一起”,利用左连接,右连接分两次将数据取出,然后用union将数据合并去重。
6.6.内容转载自:图解数据库左连接、右连接、内连接、外连接、全连接 – 积极向上的徐先生 – 博客园
7. 权限操作
7.1. 授予-GRANT
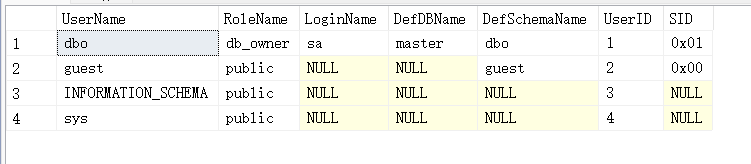
#找出数据库里面的所有用户
EXEC sp_helpuser;
#WITH GRANT OPTION 表示该用户还可以向其他用户授予其自身拥有的权限。
GRANT UPDATE,DELETE ON stu_info TO guest WITH GRANT OPTION
7.2. 拒绝-DENY
#CASCADE:对父表进行delete,update操作时,子表也会delete,update掉关联的记录。更新/删除主表中记录时自动更新/删除子表中关联记录。
DENY UPDATE ON stu_info TO guest CASCADE;
7.3. 收回-REVOKE
REVOKE DELETE ON stu_info FROM guest CASCADE;
7.4. 声明-DECLARE
#五条指令一起执行
DECLARE @username VARCHAR(20)
DECLARE @pwd VARCHAR(20)
SET @username = 'newadmin'
SELECT @pwd = 'newpwd' #跟'set'一样
SELECT '用户名:'+ @username +' 密码:' + @pwd
USE test_db
GO
DECLARE @stuscore INT
SELECT s_score From stu_info
SELECT @stuscore = s_score FROM stu_info #由最后的数据开始读取
SELECT @stuscore AS Lastscore
8. 数据输出-PRINT
DECLARE @name VARCHAR(10)='小明'
DECLARE @age INT =21
PRINT '姓名 年龄'
PRINT @name+' '+CONVERT(VARCHAR(20),@age) #不能直接输出int的数据类型
9. 流程控制
9.1. WHILE BEGIN…END语句
WHILE @count < 10
BEGIN
PRINT 'count = ' + CONVERT(VARCHAR(8),@count)
SELECT @count = @count+1
END
PRINT 'loop over count = ' + CONVERT(VARCHAR(8),@count)
DECLARE @num INT;
SELECT @num=10;
WHILE @NUM > -1
BEGIN
IF @num > 5
BEGIN
PRINT '@num 等于' + CONVERT(VARCHAR(4),@num)+'大于5 循环执行';
SELECT @num = @num -1;
CONTINUE;
END
ELSE
BEGIN
PRINT '@num 等于' + CONVERT(VARCHAR(4),@num);
BREAK;
END
END
PRINT '循环终止之后@num 等于 ' + CONVERT(VARCHAR(4),@num);
9.2. IF…ELSE语句
DECLARE @age INT;
SELECT @age=40
IF @age <30
PRINT 'This is a young man!'
ELSE
PRINT 'This is an old man!'
9.3. CASE WHEN THEN语句
在 SQL Server 中,CASE 表达式是一种用于条件逻辑判断的强大工具。它允许你在查询中基于不同的条件返回不同的值。CASE 表达式有两种主要形式:简单 CASE 表达式和搜索 CASE 表达式。然而,在大多数情况下,我们使用的是搜索 CASE 表达式,因为它允许基于多个条件进行判断。
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
[ELSE else_result]
END
condition1, condition2, … 是你要评估的布尔表达式。
result1, result2, … 是当相应条件为真时要返回的值。
ELSE else_result 是可选的,当所有条件都不满足时返回的值。如果省略 ELSE 部分,并且没有条件为真,则 CASE 表达式返回 NULL。
USE test_db
GO
SELECT s_id,s_name,
CASE s_name
WHEN '马华' THEN '班长'
WHEN '许三' THEN '学习委员'
WHEN '刘杰' THEN '体育委员'
ELSE '无'
END
AS '职位'
FROM stu_info
USE test_db
GO
SELECT s_id,s_name,s_score,
CASE
WHEN s_score > 90 THEN '优秀'
WHEN s_score > 80 THEN '良好'
WHEN s_score > 70 THEN '一般'
WHEN s_score > 60 THEN '及格'
ELSE '不及格'
END
AS '评价'
FROM stu_info
9.4. GOTO语句
USE test_db;
BEGIN
SELECT s_name FROM stu_info;
GOTO jump
SELECT s_score FROM stu_info;
jump:
PRINT '第二条SELECT语句没有执行'
END
9.5. WAITFOR
#延迟10秒执行
DECLARE @name VARCHAR(50);
SET @name='admin';
BEGIN
WAITFOR DELAY '00:00:10';
PRINT @name;
END;
9.6. RETURN
SQL Server中的RETURN语句用于从存储过程、批处理或语句块中无条件退出,并且执行RETURN之后的语句将不会被执行
RETURN [value]
DECLARE @I INT
SET @I =1
WHILE (@I <=10)
BEGIN
IF (@I=5)
BEGIN
RETURN
END
ELSE
BEGIN
SET @I = @I+1
END
END
PRINT '@I 的值:' + CAST(@I as varchar(5))
GO
PRINT '@@@@批处理后代码@@@@'
10.定义一个数据类型
10.1. 自定义一个数据类型
方法一:图形化操作
右键“用户定义数据类型”,新建
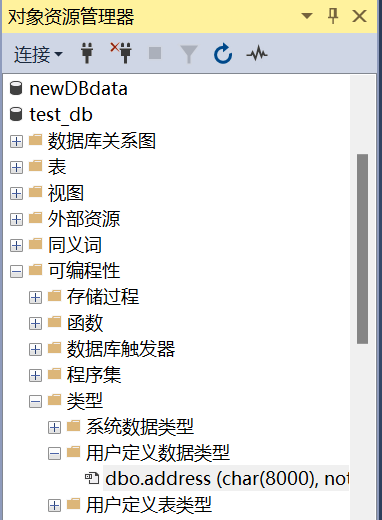
方法二:存储过程
use test_db1
sp_addtype HomeAddress,'varchar(128)','not null'
10.2. 删除对象
sp_droptype HomeAddress
11.使用聚合函数统计汇总
11.1. 使用SUM()函数求列的和
#查找价格小于9,s_id编号是101的水果
select s_id,f_name,f_price from fruits where f_price <9.0 union select s_id,f_name,f_price from fruits where s_id = 101;
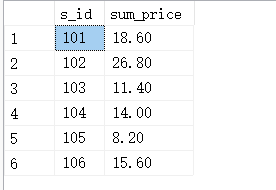
SELECT s_id,SUM(f_price) AS sum_price
FROM fruits
GROUP BY s_id;
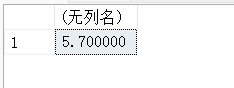
11.2. 使用AVG()函数对指定字段求平均值
SELECT AVG(f_price) AS avg_price
FROM fruits
WHERE s_id = 103;
SELECT s_id,AVG(f_price) AS avg_price
FROM fruits
GROUP BY s_id;
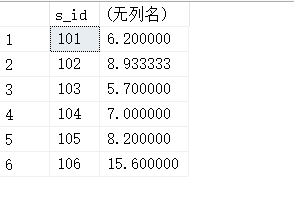
11.3. 使用MAX()函数找出指定字段中的最大值
SELECT MAX(f_price) AS max_price FROM fruits;
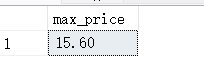
select f_name,f_price from fruits where f_price = (select max(f_price) from fruits);
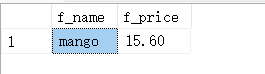
SELECT s_id,MAX(f_price) AS max_price FROM fruits GROUP BY s_id;
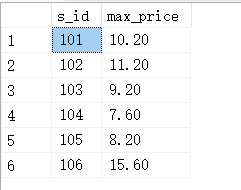
SELECT MAX(f_name) FROM fruits;
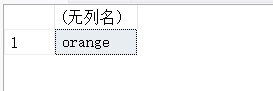
#按ASCII码来计算
由结果可以看到,MAX() 函数可以对字母进行大小判断,并返回最大的字符或者字符串值。
MAX() 函数除了用来找出最大的列值或日期值之外,还可以返回任意列中的最大值,包括返回字符类型的最大值。
在对字符类型数据进行比较时,按照字符的 ASCII 码值大小进行比较,从 a~z,a 的 ASCII 码最小,z 的最大。在比较时,先比较第一个字母,如果相等,继续比较下一个字符,一直到两个字符不相等或者字符结束为止。例如,“b”与“t”比较时,“t”为最大值;“bcd”与“bca”比较时,“bcd”为最大值。
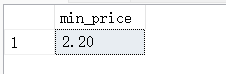
11.4. 使用MIN()函数找出指定字段中的最小值
SELECT MIN(f_price) AS min_price FROM fruits;
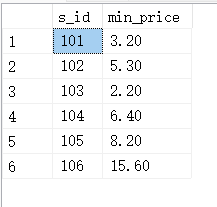
SELECT s_id,MIN(f_price) AS min_price FROM fruits GROUP BY s_id;
11.5. 使用COUNT函数统计
SELECT COUNT(*) AS '客户总数' FROM customers;
#计算表里面的总行数
SELECT COUNT(c_email) AS email_num FROM customers;
#计算有c_email的里面有数据的总行数
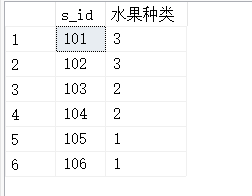
SELECT s_id '供应商',COUNT(f_name) '水果种类数目'
FROM fruits
GROUP BY s_id;
12.使用排序函数
12.1. ROW_NUMBER()-为每条记录增添递增的数字序号
#ROW_NUMBER()是一个Window函数,它为结果集的分区中的每一行分配一个连续的整数。 行号以每个分区中第一行的行号开头。
select row_number() over (order by s_id asc) as ROW_ID,s_id,f_name from fruits;
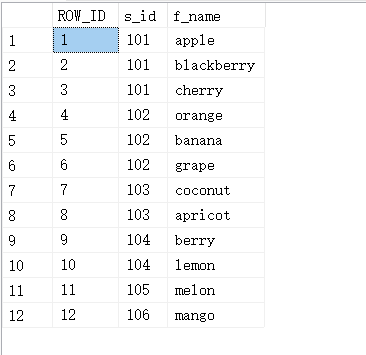
12.2. RANK()-排名
#如果两个或多个行与一个排名关联,则每个关联行将得到相同排名
SELECT RANK() OVER (ORDER BY s_id ASC) AS RANKID,s_id,f_name FROM fruits;
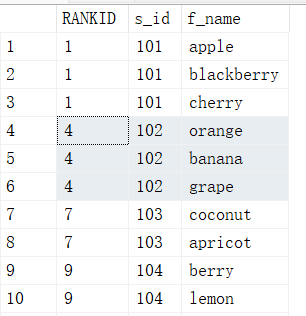
12.3. DENSE_RANK()-按顺序不间断排名
返回结果集分区中行的排名,在排名中没有任何间断
SELECT DENSE_RANK() OVER (ORDER BY s_id ASC) AS DENSEID,s_id,f_name FROM fruits;
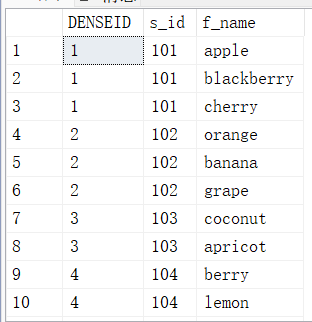
12.4. NTILE()-用来将查询结果中的记录分为N组
SELECT NTILE(5) OVER (ORDER BY s_id ASC) AS NTILEID,s_id,f_name FROM fruits;
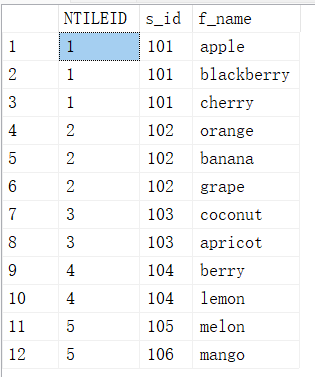
select NTILE(4) OVER (ORDER BY S_ID ASC) AS NTILEID,S_ID,F_NAME FROM FRUITS;
13. 其他各类函数(1)
13.1. ASCII()函数
ASCII()函数在SQL Server中的作用是返回字符串表达式最左侧字符的ASCII代码值。该函数接受一个字符串表达式作为参数,并返回该字符串最左侧字符的ASCII代码值。参数必须是一个char或varchar类型的字符串表达式。
#找出对应的ASCII码
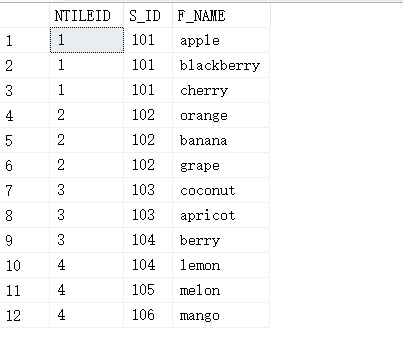
SELECT ASCII('s'),ASCII('sql'),ASCII(1);

13.2. CHAR()函数
CHAR()函数在SQL Server中的作用是将整数类型的ASCII码值转换为对应的字符。具体来说,CHAR()函数将一个整数(ASCII码值)转换为对应的字符。这个整数必须是一个介于0到255之间的值,如果输入的整数不在这个范围内,CHAR()函数将返回NULL。
#把ASCII码转字符
SELECT CHAR(115),CHAR(49);
13.3. LEFT()函数,RIGHT()函数
LEFT函数在SQL Server中的作用是用于从字符串的左侧提取子字符串。通过指定字符数,LEFT函数能够从字符串的开头提取指定数量的字符。这对于格式化数据、处理文本和提取关键信息等任务非常有用。
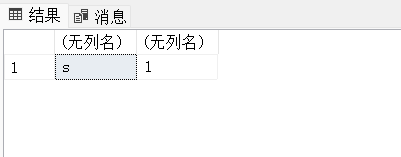
SELECT LEFT('football',4)

SQL Server中的RIGHT函数用于从字符串的右侧提取指定数量的字符。
SELECT RIGHT('football',4)

13.4. LTRIM()和RTRIM()函数
LTRIM()函数在SQL Server中的作用是去除字符串左侧的所有空格。具体来说,LTRIM()函数会从字符串的开始位置删除所有的空白字符,直到遇到第一个非空白字符为止。
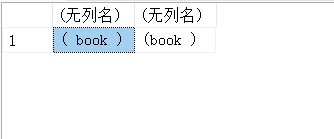
SELECT '(' + ' book ' + ')', '(' + LTRIM (' book ') + ')';
RTRIM()函数在SQL Server中的作用是去除字符串右侧的所有空格。
SELECT '(' + ' book ' + ')', '(' + RTRIM (' book ') + ')';

13.5. STR()函数-保留某数值的长度
STR函数在SQL Server中的作用是将数值数据转换为字符串数据。该函数可以处理带有小数点的数字,并且可以指定总长度和小数位数,从而生成符合特定格式的字符串。
#中间一位表示字符的总长度,最后1位是小数点后面的位数
#不能显示整数部分的其中一些
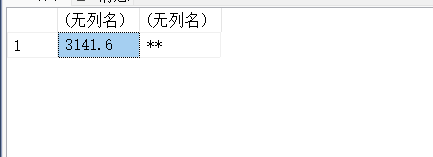
SELECT STR(3141.59,6,1),STR(123.45,2,2);
13.6. REVERSE(s)-逆序输出
SELECT REVERSE('abc');
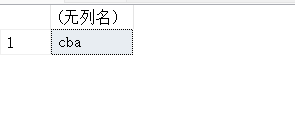
13.7. LEN(STR)-计算字符串的长度
SELECT LEN('NO'),LEN('日期'),LEN(12345);

13.8. CHARINDEX(x)-计算字符的所在位置
CHARINDEX ( expressionToFind , expressionToSearch [ , start_location ] )
expressionToFind :目标字符串,就是想要找到的字符串,最大长度为8000 。
expressionToSearch :用于被查找的字符串。
start_location:开始查找的位置,为空时默认从第一位开始查找。
#默认找到第一符合的结果,找到之后立马停止
SELECT CHARINDEX('a','banana'),CHARINDEX('a','banana',4),CHARINDEX('na','banana',4);
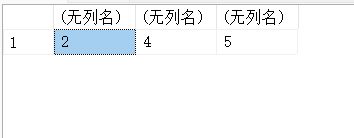
13.9. SUBSTRING(x)-保留字符串中的某一段
SUBSTRING(expression,start,length)
expression
是字符串、二进制字符串、text、image、列或包含列的表达式。不要使用包含聚合函数的表达式。
start
是一个整数,指定子串的开始位置。
length
是一个整数,指定子串的长度(要返回的字符数或字节数)。
substring() ——任意位置取子串
SELECT SUBSTRING('breakfast',1,5),
SUBSTRING('breakfast',LEN('breakfast')/2,LEN('breakfast'));

13.10. UPPER(x)函数-字母小写变大写
#小写变大写
SELECT UPPER('black'),UPPER('Black');
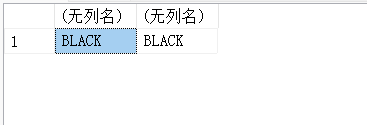
13.11. REPLACE(x)-替换
SELECT REPLACE('xxx.sqlserver2019.com','x','w');
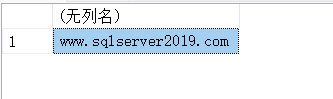
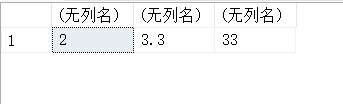
11.12. ABS(X)-返回X的绝对值
SELECT ABS(2),ABS(-3.3),ABS(-33);
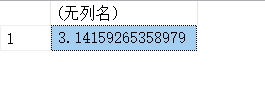
13.13. pi()函数-圆周率
SELECT pi();
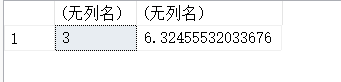
13.14.FLOOR(X)-数据舍入
在数据分析和处理中,我们经常需要对数值进行精确控制,比如将数值舍入到特定的精度。SQL Server 提供了多种数学函数,其中 FLOOR 函数就是用来执行向上舍入操作的强大工具。FLOOR 函数是 SQL Server 中的一个内置函数,它能够将数值向上舍入到最接近的整数或指定的基数。不同于四舍五入,FLOOR 函数总是向更小的数值方向舍入。
FLOOR 函数的语法
FLOOR 函数的基本语法如下:
FLOOR(numeric_expression, [integer])
numeric_expression 是要舍入的数值表达式。
integer 是可选参数,表示舍入到哪个基数的倍数。如果省略,数值将被舍入到最接近的整数。
#函数在处理负数值时,向上舍入,直接忽略小数点,向前进位
SELECT FLOOR(-21.199776) AS Result;
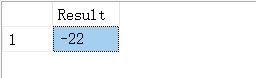
#函数在处理正数值时,直接忽略小数点,不向前进位
SELECT FLOOR(21.799776) AS Result;

13.15. RAND(x)-随机函数
#在SQL Server中,RAND()是一个函数,用于返回一个介于 0 和 1 之间的随机浮点数。这个函数在每次调用时都会生成一个新的随机数,除非在调用之间设置了种子值。
SELECT RAND(),RAND(),RAND();

#下面的查询将基于种子值 123 生成一个随机数。如果再次执行相同的查询,它将返回相同的随机数。
SELECT RAND(123);
#生成一个介于 1 和 100 之间的随机整数:
SELECT FLOOR(rand()*100)+ 1 AS Result;
13.16. ROUND(x,y)-返回接近于参数x的数
#返回接近于参数x的数,其值保留到小数点后面y位,但是保留原来位数用0来代替,若y为负值,则将保留x值到小数点左边y位。
#采用四舍五入的规则。
SELECT ROUND(1.38,1),ROUND(1.38,0),ROUND(232.38,-1),ROUND(232.38,-2),ROUND(232.82,1),ROUND(232.82,0);

13.17. SIGN(x)-返回参数的符号
#返回参数的符号
SELECT SIGN(-21),SIGN(0),SIGN(21);
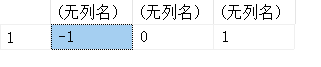
13.18. CEILING(x)-向上取整
CEILING函数在SQL Server中用于将数值向上取整到最接近的整数或指定的倍数。
CEILING(number, [significance])
number:是要向上取整的数值。
significance:(可选)是取整的基数或倍数。如果省略,则默认取整到最接近的整数
#返回不小x的最小整数,不采用四舍五入
SELECT CEILING(-3.35),CEILING(3.35);

#返回不大于x的最大整数值
SELECT FLOOR(-3.35),FLOOR(3.35);
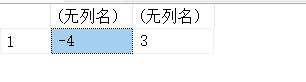
13.19. power(x,y)-计算数值表达式的指定幂次
SQL Server中的POWER()函数用于计算数值表达式的指定幂次。
#返回x的y次乘方的结果值
#2的负二次方=1÷2²=4分之1,2的2次方的倒数
SELECT POWER(2,3),POWER(2.00,-3)

13.20.SQUARE(x)-开平方
SQL Server中的SQUARE()函数用于计算一个数的平方。该函数的基本语法如下:
#返回指定浮点值x的平方
SELECT SQUARE(3),SQUARE(-3),SQUARE(0);

13.21.EXP(x)-冥运算函数
SELECT EXP(3),EXP(-3),EXP(0);
#返回e的x的乘方后的值
#e指数是一个自然常数,通常用e表示,其值约等于2.71828
13.22. SQRT(x)-返回非负数x的二次方根
#不能使用负数
SELECT SQRT(9),SQRT(40);
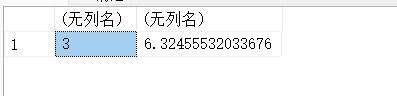
13.23. LOG(x)和LOG10(x)-对数运算函数
在 SQL Server 中,LOG 函数用于计算数值的自然对数(以 e 为底的对数)。这个函数在数学和科学计算中非常有用,特别是在处理与对数相关的数据时。
LOG (float_expression [, base])
float_expression:是要求自然对数的浮点数值表达式。
base:(可选)是用于计算对数的底数。如果省略 base,则默认计算自然对数(即以 e 为底的对数)。如果指定了 base,则 LOG 函数会返回以该底数为基准的对数。
e的定义:

#返回x的自然对数,即返回x相对于基数e的对数
#e的多少次方为3,e的多次方是6
SELECT LOG(3),LOG(6);

#返回x的基数为10的对数
#10的多少次方为100
SELECT LOG10(1),LOG10(100),LOG10(1000);

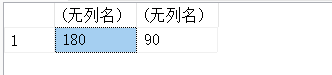
13.24. RADIANS(x)、DEGREES(x)-角度与弧度相互转换的函数
#角度转弧度
SELECT RADIANS(90.0),RADIANS(180.0);

#弧度转角度
SELECT DEGREES(PI()),DEGREES(PI()/2);
13.25. SIN(x)和ASIN(x)
SELECT SIN(PI()/2),ROUND(SIN(PI()),0);
SELECT ASIN(1),ASIN(0);
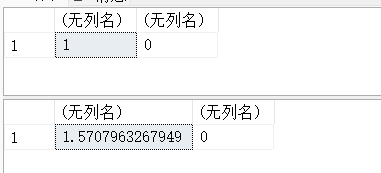
13.26. COS(x)和 ACOS(x)
SELECT COS(0),COS(PI()),COS(1);
SELECT ACOS(1),ACOS(0),ROUND(ACOS(0.5403023058681398),0);
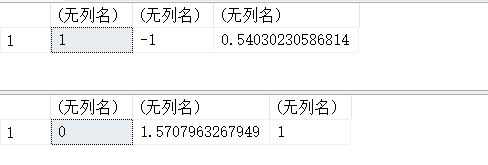
13.27. TAN(x)、ATAN(x)、COT(x) – 正切余切
SELECT TAN(0.3),ROUND(TAN(PI()/4),0);
#返回x的正切,其中x为给定的弧度值
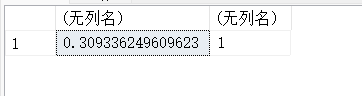
SELECT ATAN(0.30933624960962325),ATAN(1);
#ATAN()和TAN()互为反函数
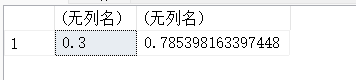
SELECT COT(0.3),1/TAN(0.3),COT(PI()/4);
#COT(x)返回x的余切,COT()和TAN()互为函数

14.其他各类函数(2)
14.1. CAST() 和 CONVERT()-转换函数
SELECT CAST('201231' AS DATE),CAST(100 AS CHAR(3)),CONVERT(TIME,'2020-05-01 12:11:10');
#第一个,转换为日期类型
#第二个,转换为字符串类型
#第三个,datetime类型转换为time类型

14.2. TEXTPTR()-文本指针
USE test_db
GO
CREATE TABLE t1 (c1 int, c2 text)
INSERT t1 VALUES('1','This is text.')
SELECT c1, TEXTPTR(c2) FROM t1 WHERE c1 = 1
#返回本指针
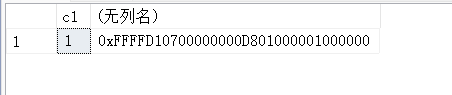
14.3. TEXTVALID()-检查特定文本指针是否有效
SELECT c1, 'This is text.' = TEXTVALID('t1,c2',TEXTPTR(c2)) FROM t1;
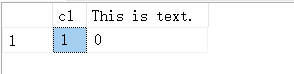
14.4. GETDATE()-返回数据库系统的日期和时间
SELECT GETDATE();
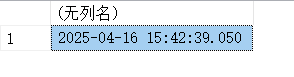
14.5. UTCDATE()-返回当前的UTC日期值
SELECT GETUTCDATE();
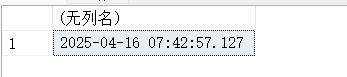
14.6. DAY(d)-返回月内指定日期的天数
SELECT DAY('2020-11-12 01:01:01');
#返回指定日期d是一个月中的第几天,范围是从1到31,该函数再功能上等价与DATEPAT(dd,d)
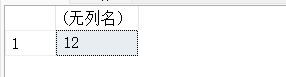
14.7. MONTH(d)-返回指定日期d中月份的整数值
SELECT MONTH('2020-04-12 01:01:01');
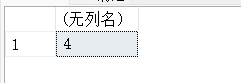
14.8. YEAR(d)-返回指定日期d中年份的整数值
SELECT YEAR('2020-02-03'),YEAR('2021-02-03');
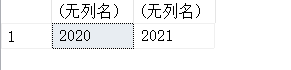
14.9. DATENAME(dp,d)-返回日期中定制部分的整数值
SELECT DATENAME(year,'2020-11-12 01:01:01'),DATENAME(weekday,'2020-11-12 01:01:01'),DATENAME(dayofyear,'2020-11-12 01:01:01');

14.10. DATEADD(dp,num,d)-返回指定日期加上一个时间段的新日期
SELECT
DATEADD(year,1,'2020-11-12 01:01:01'),
DATEADD(month,1,'2020-11-12 01:01:01'),
DATEADD(hour,1,'2020-11-12 01:01:01');

14.11. COL_LENGTH(table,column-返回表中指定字段的长度值
USE test_db
GO
SELECT COL_LENGTH('stu_info','s_name');
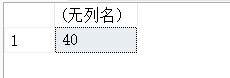
14.12. COL_NAME(table_id,column_id)-返回表中指定字段的名称
SELECT COL_NAME(OBJECT_ID('test_db.dbo.stu_info'),1);
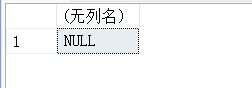
14.13. DATALENGTH(expression)-返回数据表达式得数据得实际长度
USE test_db;
GO
SELECT DATALENGTH(s_name) FROM stu_info WHERE s_id = 1;
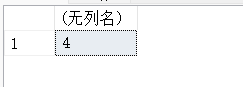
14.14. DB_ID(database_name)-返回数据库得编号
SELECT DB_ID('master'),DB_ID('test_db')
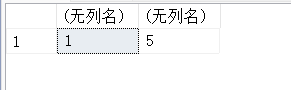
14.15. DB_NAME(database_id)- 函数返回数据库得名称
USE master
GO
SELECT DB_NAME(),DB_NAME(DB_ID('test_db'));
USE master
GO
SELECT DB_NAME(),DB_NAME(6);

14.16. GETANSINULL(database_name) – 返回当前数据库默认得NULL值
SELECT GETANSINULL('test_db')
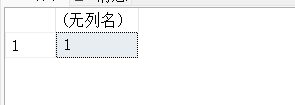
14.17. HOST_ID() – 返回计算机得标识号
SELECT HOST_ID();

14.18. HOST_NAME – 返回服务端计算机名称
SELECT HOST_NAME();
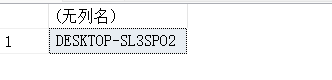
14.19. OBJECT_ID() – 返回数据库对象编号
#OBJECT_ID(database_name.schema_name.object_name,object type)
SELECT OBJECT_ID('test_db.dbo.stu_info');
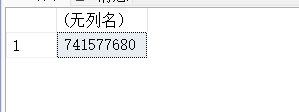
14.20. SUSER_ID – 返回用户的SID
SELECT SUSER_SID('DESKTOP-SL3SPO2\Administrator')
SELECT SUSER_SID('sa');
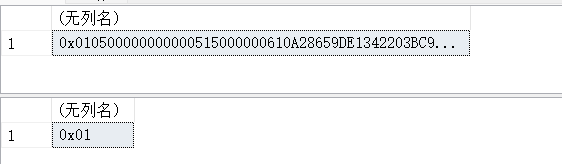
14.21. SUSER_SNAME – 返回用户的登录名
SELECT SUSER_SNAME(0x010500000000000515000000610A28659DE1342203BC96CEF4010000);
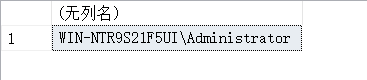
14.22. OBJECT_NAME – 返回数据库对象名称
SELECT OBJECT_NAME(645577338,DB_ID('test_db')),
OBJECT_ID('test_db.dbo.stu_info');
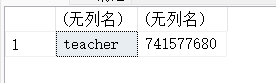
14.23. USER_ID – 返回数据用户ID
USE test_db;
SELECT USER_ID();

14.24. USER_NAME(1) – 返回数据库用户名
USE test_db;
SELECT USER_NAME();
15.动态查询
USE test_db
GO
DECLARE @id INT;
DECLARE @sql varchar(8000)
SELECT @id=101;
SELECT @sql = 'SELECT f_name,f_price
FROM fruits
WHERE s_id = ';
exec (@sql + @id);
16.经典习题
16.1.经典习题
- 创建数据库Market,在Market中创建数据表customers,customers表结构如表3-2所示,按要求进行操作。
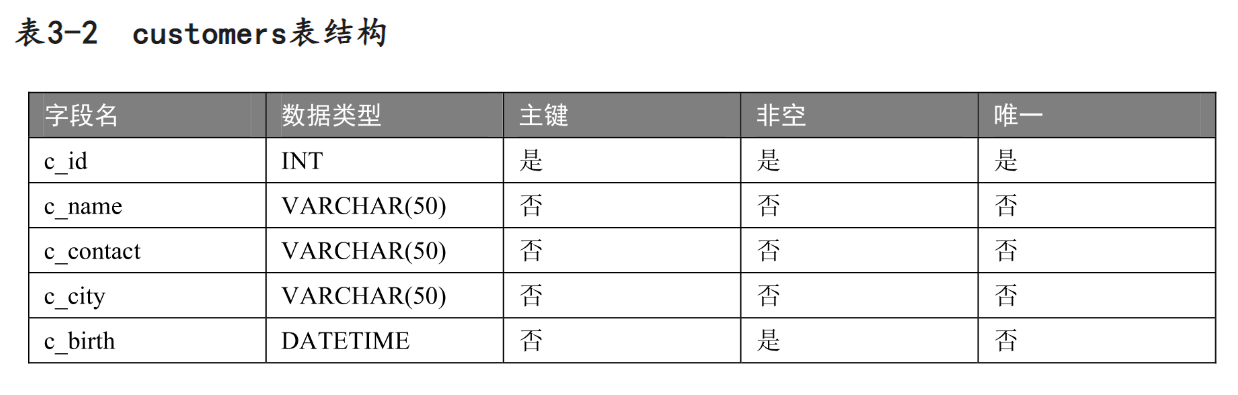
1.创建数据库Market。
2.创建数据表customers,再c_id字段上添加主键约束,在c_birth字段上添加非空约束。
3.将c_name字段数据类型改为VARCHAR(70)。
4.将c_contact字段改名为c_phone。
5.增加c_gender字段,数据类型为CHAR(1)。
6.将表明修改为customers_info。
7.删除字段c_city。
(1)创建数据库Market
CREATE DATABASE [Market] ON PRIMARY
(
NAME = Market,
FILENAME = 'D:\SQL server 2019\Market\market_db.mdf',
SIZE = 10MB,
MAXSIZE = 50MB,
FILEGROWTH = 5%
)
LOG ON
(
Name = Market_log,
FILENAME = 'D:\SQL server 2019\Market\market_log.ldf',
SIZE = 2MB,
FILEGROWTH = 5%
)
(2)创建数据表customers,再c_id字段上添加主键约束,在c_birth字段上添加非空约束。
USE Market
CREATE TABLE customers
(
c_id INT PRIMARY KEY NOT NULL,
c_name VARCHAR(50),
c_contact VARCHAR(50),
c_city VARCHAR(50),
c_birth DATETIME NOT NULL
)
(3)将c_name字段数据类型改为VARCHAR(70)。
ALTER TABLE customers
ALTER COLUMN c_name VARCHAR(70)
(4)将c_contact字段改名为c_phone。
exec sp_rename 'customers.c_name','c_phone'
(5)增加c_gender字段,数据类型为CHAR(1)
ALTER TABLE customers ADD c_gender CHAR(1)
(6)将表名修改为customers_info。
exec sp_rename 'customers','customers_info'
(7)删除字段c_city。
ALTER TABLE customers_info DROP COLUMN c_city
在Market中创建数据表orders,orders表结构如表3-3所示,按要求进行操作。
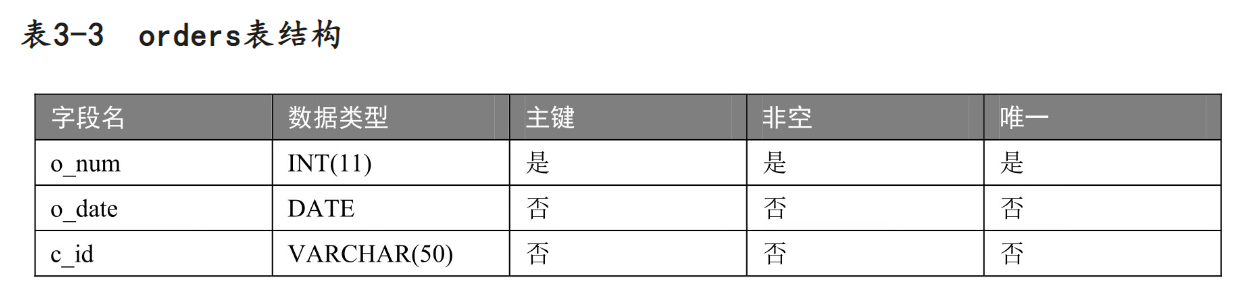
(1)创建数据表orders,在o_num字段上添加主键约束,在c_id字段上添加外键约束,关联customers表中的主键c_id。
(2)删除orders表的外键约束,然后删除表customers。
SQL SERVER里面没有INT(11)的写法,这个写法见于MYSQL,括号里的数字表示“显示宽度”,仅控制客户端显示时补零的对齐方式(如ZEROFILL)
(1)创建数据表orders,在o_num字段上添加主键约束,在c_id字段上添加外键约束,关联customers表中的主键c_id。
USE Market
CREATE TABLE orders
(
o_num INT PRIMARY KEY NOT NULL,
o_date DATE,
c_id INT,
CONSTRAINT fk_cid FOREIGN KEY (c_id) REFERENCES customers_info(c_id)
)
(2)删除orders表的外键约束,然后删除表customers。
ALTER TABLE orders DROP CONSTRAINT fk_cid
USE Market DROP TABLE customers_info‘
16.2.经典习题
16.2.1.SQL Server系统数据类型都有哪些,各种数据类型都有什么特点?
1.整数数据类型,特点:
整数数据类型是常用的数据类型之一,主要用于存储数值,可以直接进行数据运算而不必使用函数转换。
2.浮点数据类型,特点:
浮点数据类型存储十进制小数,它是用于表示浮点数值数据的一种数据类型。浮点数据为近似值;浮点数值的数据在SQL Server中采用只入不舍的方式进行存储,即要舍入的数是一个非零数时,对其保留数字部分的最低有效位上的数字加1,并进行必要的进位。
3.字符数据类型,特点:
用来储存各种字母、数字符号和特殊符号。在使用字符数据类型时,需要在其前后加入英文单引号或者双引号。
4.日期和时间数据类型,特点:
存储用字符串表示的日期数据,可以表示0001-01-01到9999-12-31(公元元年1月1日到公元9999年12月31日)间的任意日期值。数据格式为“YYYY-MM-DD”。
5.二进制数据类型,特点:
类型:BINARY, VARBINARY, VARBINARY(MAX)
特点:
存储内容:二进制数据(如图片、文件、序列化对象等)。
固定长度:BINARY(n) 固定长度为 n 字节,不足时填充零。
可变长度:VARBINARY(n) 最大长度为 n 字节,按实际数据长度存储。
大容量存储:VARBINARY(MAX) 支持最大 2GB 数据,替代已弃用的 IMAGE 类型。
适用场景:非文本类数据(如加密数据、文件内容)。
6.特殊数据类型,特点:
常见类型:UNIQUEIDENTIFIER, TIMESTAMP, SQL_VARIANT, XML, SPATIAL(GEOMETRY/GEOGRAPHY)
特点:
UNIQUEIDENTIFIER:存储全局唯一标识符(GUID),适用于分布式系统唯一键。
TIMESTAMP:自动生成的 8 字节二进制值,反映数据修改版本(非时间戳)。
SQL_VARIANT:可存储多种数据类型(如 INT, VARCHAR),但需谨慎使用(类型转换开销大)。
XML:存储结构化 XML 数据,支持 XQuery 查询和索引优化。
空间类型:GEOMETRY(平面坐标)和 GEOGRAPHY(地理坐标),用于地理信息系统(GIS)。
7.hierarchid,特点:
用途:高效表示树形层次结构(如组织结构、目录树)。
特点:
路径编码:以二进制形式存储节点路径(如 /1/2/3/),压缩存储空间。
内置方法:提供 GetAncestor()、GetDescendant()、GetLevel() 等方法,简化层次查询。
索引友好:支持深度优先和广度优先索引策略,优化查询性能。
动态更新:支持插入、移动节点操作,无需重构整棵树。
8.用户自定义的数据类型,特点:
定义方式:
别名类型:基于现有类型扩展(如 CREATE TYPE PhoneNumber FROM VARCHAR(20))。
CLR 类型:通过 .NET 程序集创建复杂类型(需启用 CLR 集成)。
特点:
数据一致性:统一字段格式(如邮政编码、电话号码),减少冗余约束。
作用域:仅在定义它的数据库中有效。
约束与默认值:可绑定规则(Rules)或默认值(Defaults)到 UDT。
局限性:无法直接修改,需删除后重建;CLR UDT 需维护程序集。
16.2.2.局部变量和全局变量有什么区别?
局部变量是用户可自定义的变量,它的作用范围仅在程序内部。在程序中通常用来储存从表中查询到的数据,或当作程序执行过程中暂存变量使用。
全局变量是sql server(WINDOWS平台上强大的数据库平台)系统内部使用的变量,其作用范围并不局限于某一程序,而是任何程序均可随时调用全局变量通常存储一些sql server(WINDOWS平台上强大的数据库平台)的配置设定值和效能统计数据。用户可在程序中用全局变量来测试系统的设定值或Transact-SQL命令执行后的状态值。
16.2.3.SQL Server运算符有哪几类,每一种运算符的使用方法和特点是什么?
包括算术运算符、逻辑运算符、比较运算符、位运算符、其他运算符
16.3.经典习题
1.Transact-SQL语句包含哪些具体内容?
2.使用Transact-SQL语句创建名为zooDB的数据库。
3.使用Transact-SQL语句删除zooDB数据库。
4.声明整数变量@var,使用CASE流程控制语句判断@VAR值等于1、等于2,或者两者都不等。
当@var值为1时,输出字符串"var is 1";
当@var值为2时,输出字符串"var is 2";
否则输出字符串"var is not 1 or 2"。
(1)Transact-SQL语句包含哪些具体内容?
T-SQL 的核心功能包括:
数据定义(DDL)与 数据操作(DML)。
事务控制与 权限管理(DCL)。
过程化编程(流程控制、错误处理)。
代码封装(存储过程、函数)。
动态 SQL 和 高级查询优化。
(2)使用Transact-SQL语句创建名为zooDB的数据库,指定的数据库参数如下:
逻辑文件名称:zooDB_data。
主文件大小:5MB
最大增长空间:15MB
文件增长大小为:5%
CREATE DATABASE [zooDB_data] on PRIMARY
(
NAME = zooDB_data,
FILENAME = 'D:\SQL server 2019\zooDB\zooDB_data.mdf',
SIZE = 5MB,
MAXSIZE = 15MB,
FILEGROWTH = 5%
)
LOG on
(
NAME = zooDB_log,
FILENAME = 'D:\SQL server 2019\zooDB\zooDB_log.ldf',
SIZE = 5MB,
MAXSIZE = 15MB,
FILEGROWTH = 5%
)
(3)使用Transact-SQL语句删除zooDB数据库。
DROP DATABASE zooDB_data;
(4)声明整数变量@var,使用CASE流程控制语句判断@VAR值等于1、等于2,或者两者都不等。当@var值为1时,输出字符串”var is 1″;当@var值为2时,输出字符串”var is 2″,否则输出字符串”var is not 1 or 2″。
DECLARE @var INT;
SELECT @var = 3;
SELECT
CASE
WHEN @var = 1 then 'var is 1'
WHEN @var = 2 then 'var is 2'
ELSE 'var is not 1 or 2'
END AS RESULT
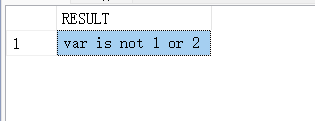
declare @var int
select @var = 0
while @var <= 2
begin
select @var=@var+1
select case
when @var=1 then 'var is 1'
when @var=2 then 'var is 2'
else 'var is not 1 or 2'
end as result
end

16.4.经典习题-计算题
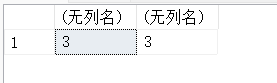
(1)计算18除以5的商和余数。
SELECT FLOOR(18/5),FLOOR(18%5);
#返回不大于x的最大整数值
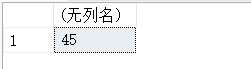
(2)将弧度值PI()/4转换为角度值。
SELECT DEGREES(PI()/4);
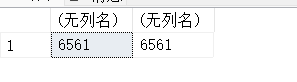
(3)计算9的4次方值。
SELECT SQUARE(SQUARE(9)),POWER(9,4);
(4)保留浮点值3.14159到小数点后面2位。
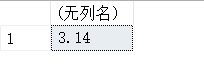
SELECT ROUND(3.14159,2);
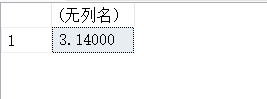
SELECT STR(3.14159,4,2);
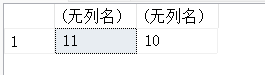
(5)分别计算字符串’Hello World!’和’University’的长度
SELECT LEN('Hello World!'),LEN('University');
(6)从字符串’Nice to meet you!’中获取子字符串’meet!’。
SELECT SUBSTRING('Nice to meet you!',9,4);

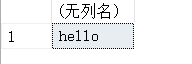
(7)除去字符串’h e l l o’中的空格。
SELECT REPLACE('h e l l o',' ','');
(8)将字符串’SQLServer’逆序输出。
SELECT REVERSE('SQLSever');

(9)字符串’SQLServerSQLServer’中从第4个字母开始查找字母Q第一次出现的位置。
SELECT CHARINDEX('Q','SQLServerSQLServer',4);
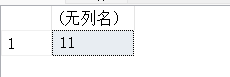
(10)计算当前日期是一年的第几天。
#dayofyear,返回当前日期是一年的几天;GETUTDATE,系统时间。
SELECT DATENAME(dayofyear,GETUTCDATE());
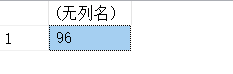
(11)计算当前日期是一周中的第几个工作日
SELECT DATENAME(weekday,GETUTCDATE());

(12)计算’1929-02-14’与当前日期之间相差的年份
SELECT YEAR(GETUTCDATE()) - YEAR('1929-02-14');
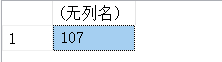
(13)计算’1929-02-14’与当前日期之间的天数
SELECT DATEDIFF(DAY,'1929-02-14',GETUTCDATE()) AS DAYSINCESTART;

16.5.经典练习
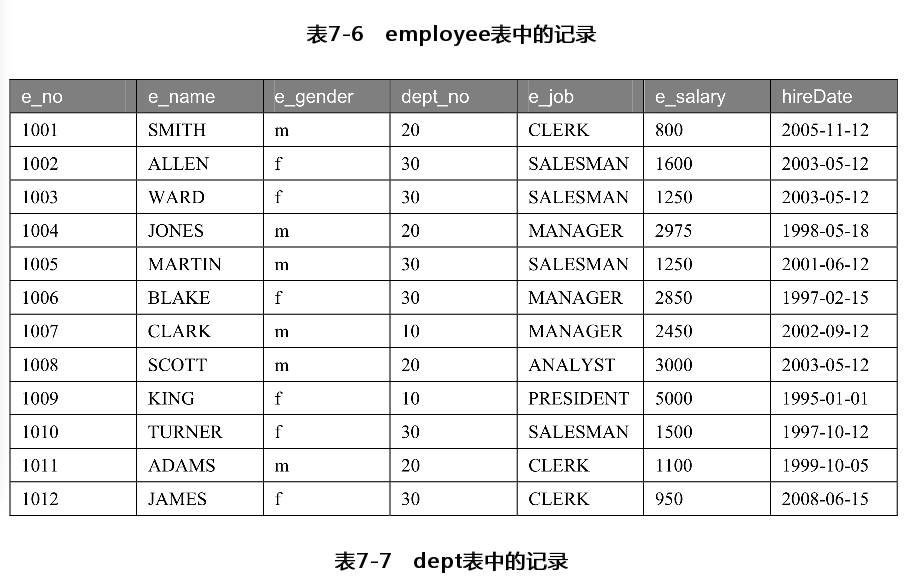
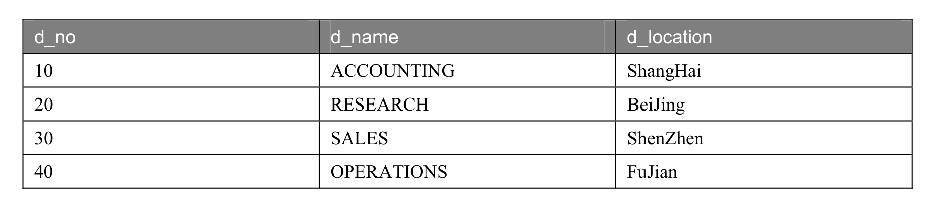
0.创建表
1.查询销售人员(SALESMAN)的最低工资。
2.查询名字以字母N或者S结尾的记录。
3.查询在BeiJing工作的员工的姓名和职务。
4.使用左外连接方式查询employee表和dept表
5.查询所有2001到2005年入职的员工的信息,查询部门编号为20和30的员工信息并使用UNION合并两个查询结果。
6.查询所有2001到2005年入职的员工的信息,并且部门编号为20和30的员工信息的查询结果。
7.使用LIKE关键字查询员工姓名中包含字母a的记录。
创建表
#父表:
CREATE TABLE dept
(
d_no INT NOT NULL PRIMARY KEY, --部门编号
d_name VARCHAR(50) NOT NULL, --部门名称
d_location VARCHAR(100) --部门地址
);
#子表:
USE test_db
GO
CREATE TABLE employee
(
e_no INT PRIMARY KEY NOT NULL, --员工编号
e_name VARCHAR(50) NOT NULL, --员工姓名
e_gender CHAR(2), --员工性别
dept_no INT NOT NULL, --部门编号
e_job VARCHAR(50) NOT NULL, --职位
e_salary INT NOT NULL, --薪水
hireDate DATE NOT NULL, --入职日期
CONSTRAINT dno_fk FOREIGN KEY (dept_no) REFERENCES dept(d_no)
);
#主表的字段数据类型,必须和外键表的外键字段类型要类似。
插入数据
INSERT INTO dept
values(10,'accounting','Shanghai'),
(20,'research','Beijing'),
(30,'sales','ShenZhen'),
(40,'operations','Fujian');
INSERT INTO employee VALUES('1001','SMITH','m','20','CLERK','800','2005-11-12'),
('1002','ALIEN','f','30','SALESMAN','1600','2003-05-12'),
('1003','WARD','f','30','SALESMAN','1250','2003-05-12'),
('1004','JONES','m','20','MANAGER','2975','1998-05-18'),
('1005','MARTIN','m','30','SALESMAN','1250','2001-06-12'),
('1006','BLAKE','f','30','MANAGER','2850','1997-02-15'),
('1007','CLARK','m','10','MANAGER','2450','2002-09-12'),
('1008','SCOTT','m','20','ANALYST','3000','2003-05-12'),
('1009','KING','f','10','PRESIDENT','5000','1995-01-01'),
('1010','TURNER','f','30','SALESMAN','1500','1997-10-12'),
('1011','ADAMS','m','20','CLERK','1100','1999-10-05'),
('1012','JAMES','f','30','CLERK','950','2008-06-15');
修改外键
#先删除,后添加
USE test_db
GO
ALTER TABLE dept DROP CONSTRAINT fk_dno
USE test_db
GO
ALTER TABLE employee ADD CONSTRAINT fk_dno FOREIGN KEY (dept_no) REFERENCES dept(d_no);
#添加外键,没法继续题目
操作:
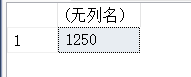
(1)查询销售人员(SALESMAN)的最低工资。
USE test_db
GO
select min(e_salary) AS 'minimum wage' from employee where e_job = 'SALESMAN'
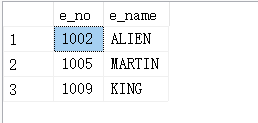
(2)查询名字以字母N或者S结尾的记录。
USE test_db
GO
SELECT e_no,e_name FROM employee WHERE e_name LIKE '%[NG]';
(3)查询在BeiJing工作的员工的姓名和职务。
USE test_db
GO
SELECT e_no,e_name,e_job FROM employee WHERE dept_no = (select d_no from dept where d_location = 'BeiJing');
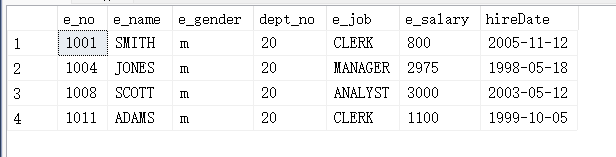
(4)使用左外连接方式查询employee表和dept表
select * from employee left outer join dept ON employee.dept_no = dept.d_no;
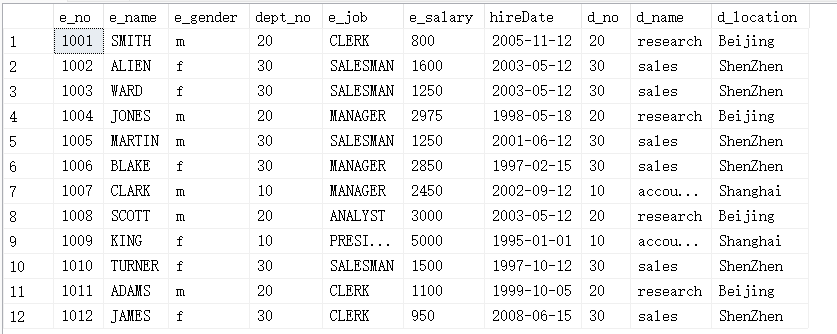
(5)查询所有2001到2005年入职的员工的信息,查询部门编号为20和30的员工信息并使用UNION合并两个查询结果。
select * from employee where year(hireDate) between 2001 and 2005 union select * from employee where dept_no in (20,30);
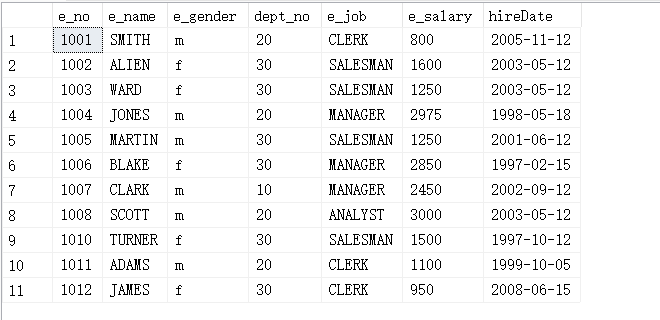
(6)查询所有2001到2005年入职的员工的信息,并且部门编号为20和30的员工信息的查询结果。
select * from employee where dept_no in (20,30) and (year(hireDate) between 2001 and 2005);
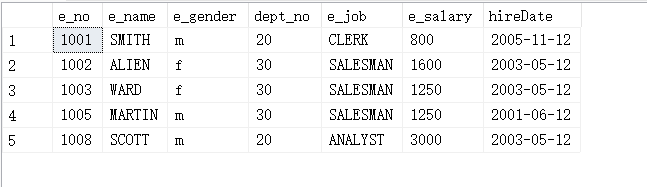
(7)使用LIKE关键字查询员工姓名中包含字母a的记录。
select * from employee where e_name like '%a%';
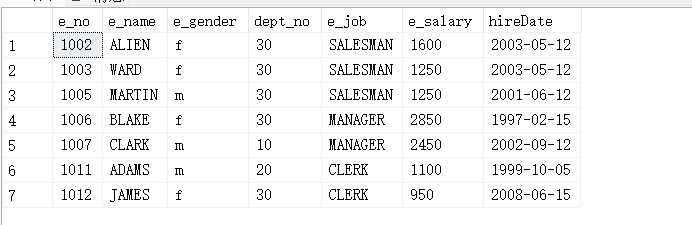
17.其他
17.1.查看当前SQL Server的版本信息和服务器名称
SELECT @@VERSION AS 'SQL server 版本信息',@@SERVERNAME AS '服务器名称'
17.2.创建局部变量
DECLARE @MyCounter INT
SELECT @MyCounter = 100
SELECT @MyCounter
GO
17.3.通过查询语句给变量赋值
DECLARE @rows int
SET @rows=(SELECT COUNT(*) FROM customers)
SELECT @rows
GO
USE test
GO
DECLARE @memberType varchar(100)
SET @memberType = 'VIP'
SELECT RTRIM(FirstName)+' '+RTRIM(LastName) AS Name, @memberType AS GRADE #
FROM member
GO
#RTRIM 字符串函数,它返回一个删除了尾随空格的字符串。
17.4.脚本
USE test
GO
DECLARE @mycount int
CREATE TABLE person
(
id INT NOT NULL PRIMARY KEY,
name VARCHAR(40) NOT NULL DEFAULT '',
age INT NOT NULL DEFAULT 0,
info VARCHAR(50) NULL
);
INSERT INTO person (id,name,age) VALUES (1,'Green',21);
INSERT INTO person (age,name,id,info) VALUES (22,'suse',2,'dancer');
SET @mycount =(SELECT COUNT(*) FROM person)
SELECT @mycount
GO
18.疑难解惑
18.1.排序时NULL值如何处理
在处理查询结果中没有重复值时,如果指定的列中有多个NULL值,则作为相同的值对待,显示结果中只有一个空值。对于使用ORDER BY子句排序得到的结果集中,若存在NULL值,升序排序时有NULL值的记录将显示在最前面,而降序时NULL值将显示在最后面。
18.2.DISTINCT可以应用于所有的列吗
查询结果中,如果需要对字段(即数据表的列)进行降序排序,可以使用DESC,这个关键字只能对其前面的字段降序排序。例如,要对多个字段都进行降序排序,必须要在每一字段名后面加DESC关键字。而DISTINCT不同,它不能部分使用,换句话说,DISTINCT关键字应用于所有字段而不仅是它后面的第一个指定的字段,例如,查询3个字段s_id、f_name、f_price,如果不同记录的这3个字段的组合值都不同,则所有记录都会被查询出来
18.3.父表与子表的关系
在数据库关系设计中,父表(Parent Table)和子表(Child Table)是通过外键(Foreign Key)关系定义的。以下是确定两者的核心方法:
18.3.1. 外键的指向关系
父表:被外键引用的表,必须包含主键(Primary Key)或唯一键(Unique Key)。
子表:包含外键列的表,该列的值必须存在于父表的主键中。
示例:
-- 父表(部门信息)
CREATE TABLE dept (
d_no INT PRIMARY KEY, -- 主键,被外键引用
d_name VARCHAR(50)
);
-- 子表(员工信息)
CREATE TABLE employee (
e_no INT PRIMARY KEY,
dept_no INT, -- 外键,指向父表 dept 的主键 d_no
FOREIGN KEY (dept_no) REFERENCES dept(d_no)
);
dept是父表(被引用的主键d_no)。employee是子表(包含外键dept_no)。
18.3.2. 数据依赖关系
- 父表:数据可独立存在(如部门信息)。
- 子表:数据依赖父表存在(如员工必须属于某个部门)。
操作顺序验证:
- 必须先插入父表数据:
无法在子表插入dept_no=101的员工,除非dept表中已存在d_no=101的部门。 - 删除父表数据时受限:
如果子表有记录引用父表某行,默认无法直接删除父表的该行(除非使用级联删除)。
在数据库关系设计中,父表(Parent Table)和子表(Child Table)是通过外键(Foreign Key)关系定义的。以下是确定两者的核心方法:
18.3.3. 外键的指向关系
- 父表:被外键引用的表,必须包含主键(Primary Key)或唯一键(Unique Key)。
- 子表:包含外键列的表,该列的值必须存在于父表的主键中。
示例:
-- 父表(部门信息)
CREATE TABLE dept (
d_no INT PRIMARY KEY, -- 主键,被外键引用
d_name VARCHAR(50)
);
-- 子表(员工信息)
CREATE TABLE employee (
e_no INT PRIMARY KEY,
dept_no INT, -- 外键,指向父表 dept 的主键 d_no
FOREIGN KEY (dept_no) REFERENCES dept(d_no)
);
dept是父表(被引用的主键d_no)。employee是子表(包含外键dept_no)。
18.3.4. 数据依赖关系
- 父表:数据可独立存在(如部门信息)。
- 子表:数据依赖父表存在(如员工必须属于某个部门)。
操作顺序验证:
- 必须先插入父表数据:
无法在子表插入dept_no=101的员工,除非dept表中已存在d_no=101的部门。 - 删除父表数据时受限:
如果子表有记录引用父表某行,默认无法直接删除父表的该行(除非使用级联删除)。
18.3.5. 逻辑关系分析
父表通常表示“一”的一方,子表表示“多”的一方,体现“一对多”关系。
例如:
- 一个部门(父表)可以有多个员工(子表)。
- 一个订单(父表)可以有多个订单项(子表)。